A zero-boundary database architecture.
From wire to GPU on Apple Silicon.
Treating data flows as a compute primitive.
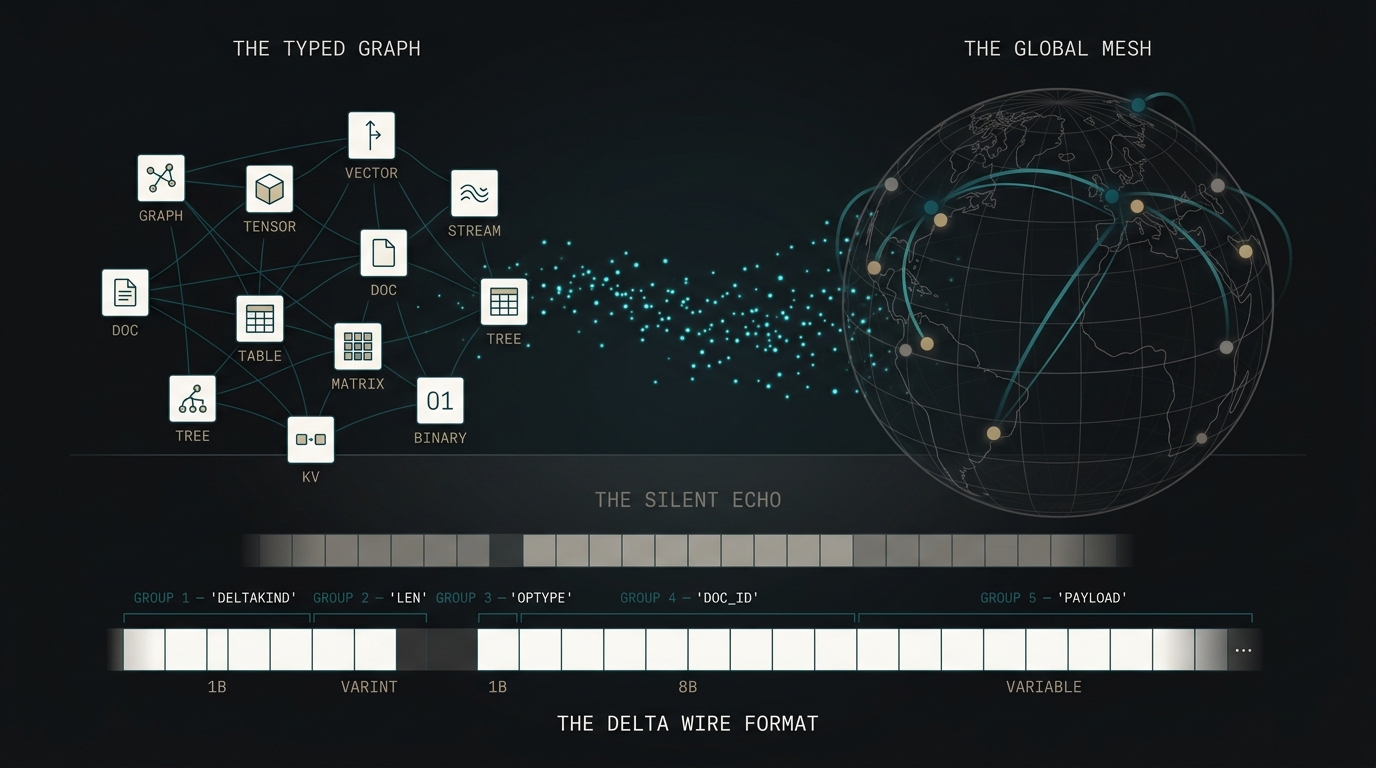
A data engine for complex data structures — trees, graphs, streams, tensors, tables, vectors.
Structure-aware. Zero-copy from network to compute. mgraph is data collaboration as a primitive.

Vector and relational database built for Apple Silicon’s unified memory.
Treats the GPU as primary compute. CPU and GPU on shared memory for a previously unseen class of operations.
A direct line from wire to GPU.
Together, they provide a direct line from wire to GPU compute that was previously impossible.
Both are industry firsts. A structure-aware zero-copy data engine, and a database that treats the Apple Silicon GPU as primary compute. No existing system provides this path.
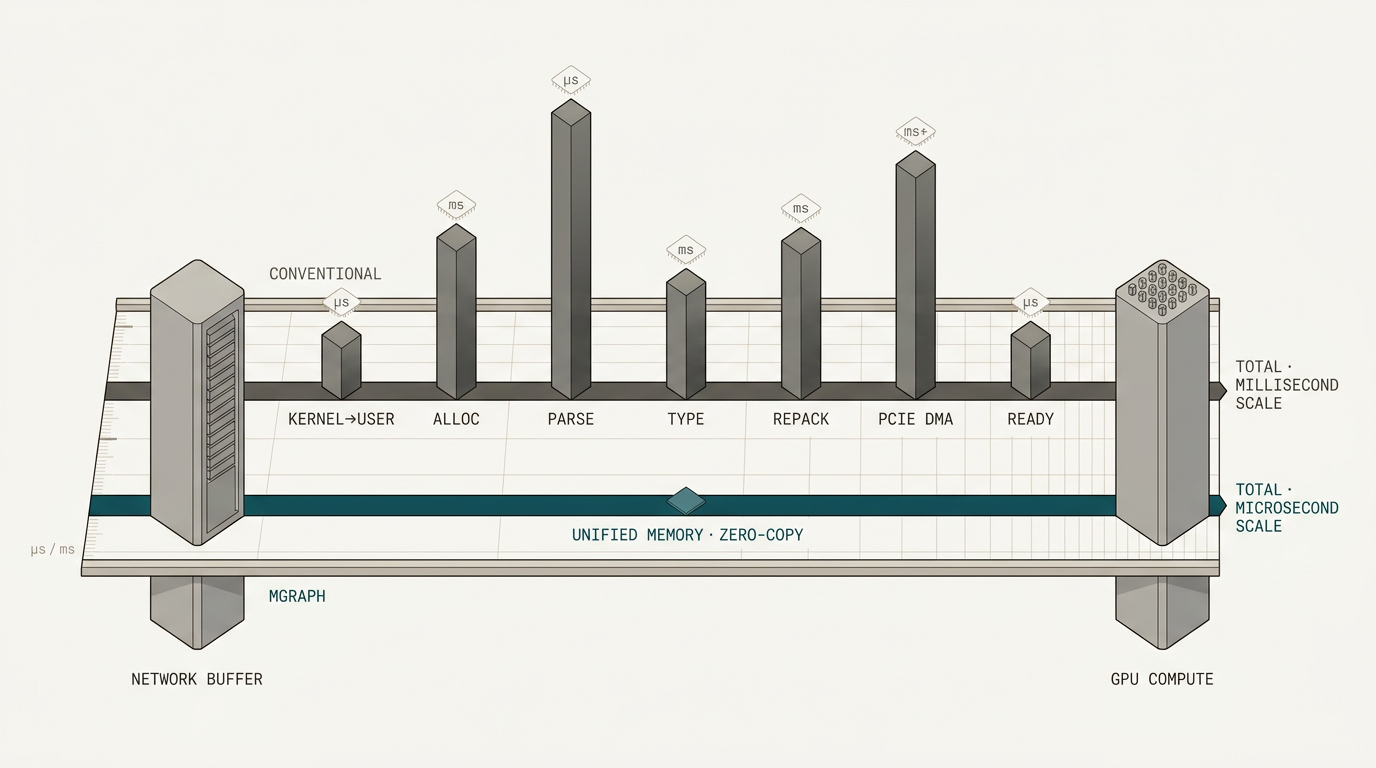
Zero serialisation from network to compute.
Structured payloads moved without translation at the boundary.
The first database built for Apple Silicon’s GPU.
On-device vector retrieval on hardware every developer already owns.
Coordinated CPU+GPU execution on shared memory.
A property unique to Apple’s unified memory architecture.
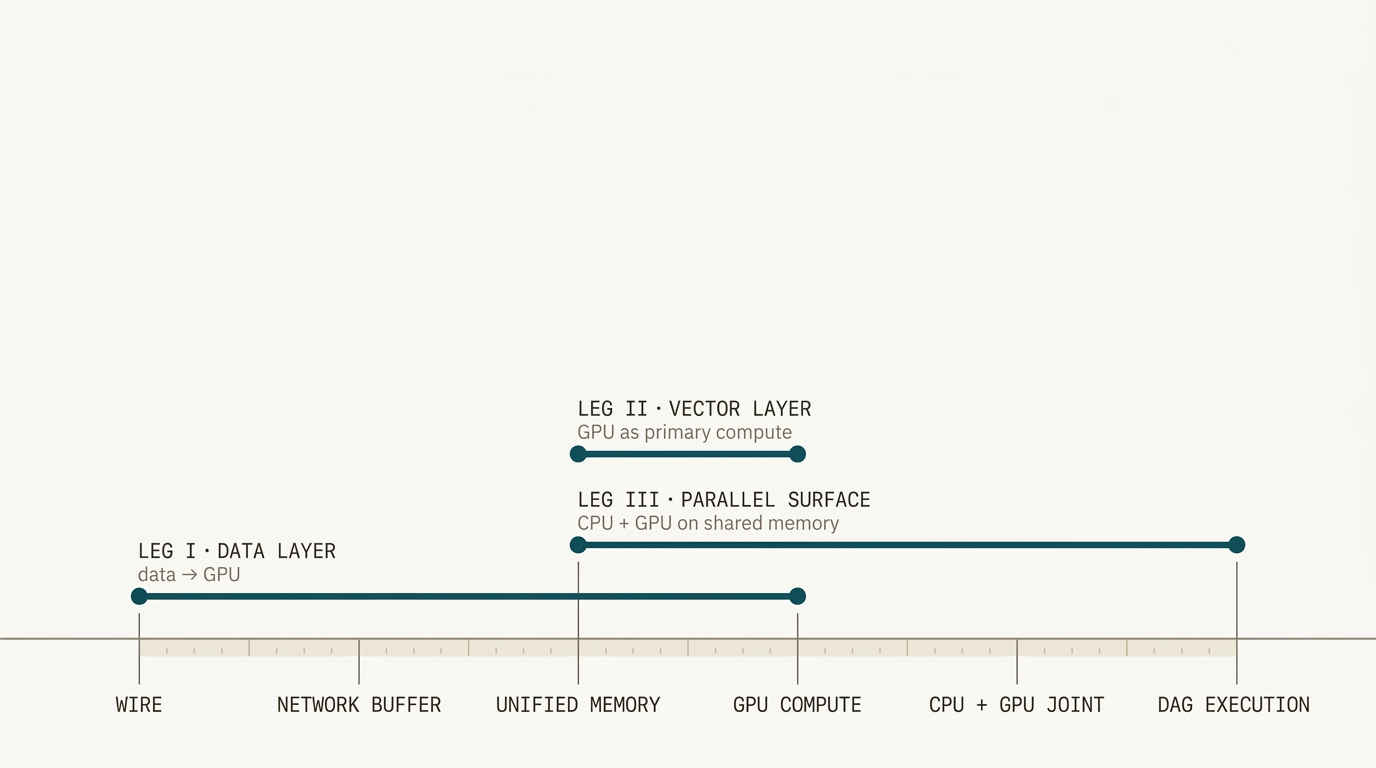
The data leg.
Structure-aware, zero-copy delta propagation at message-broker throughput — with database-grade atomic guarantees across complex types.
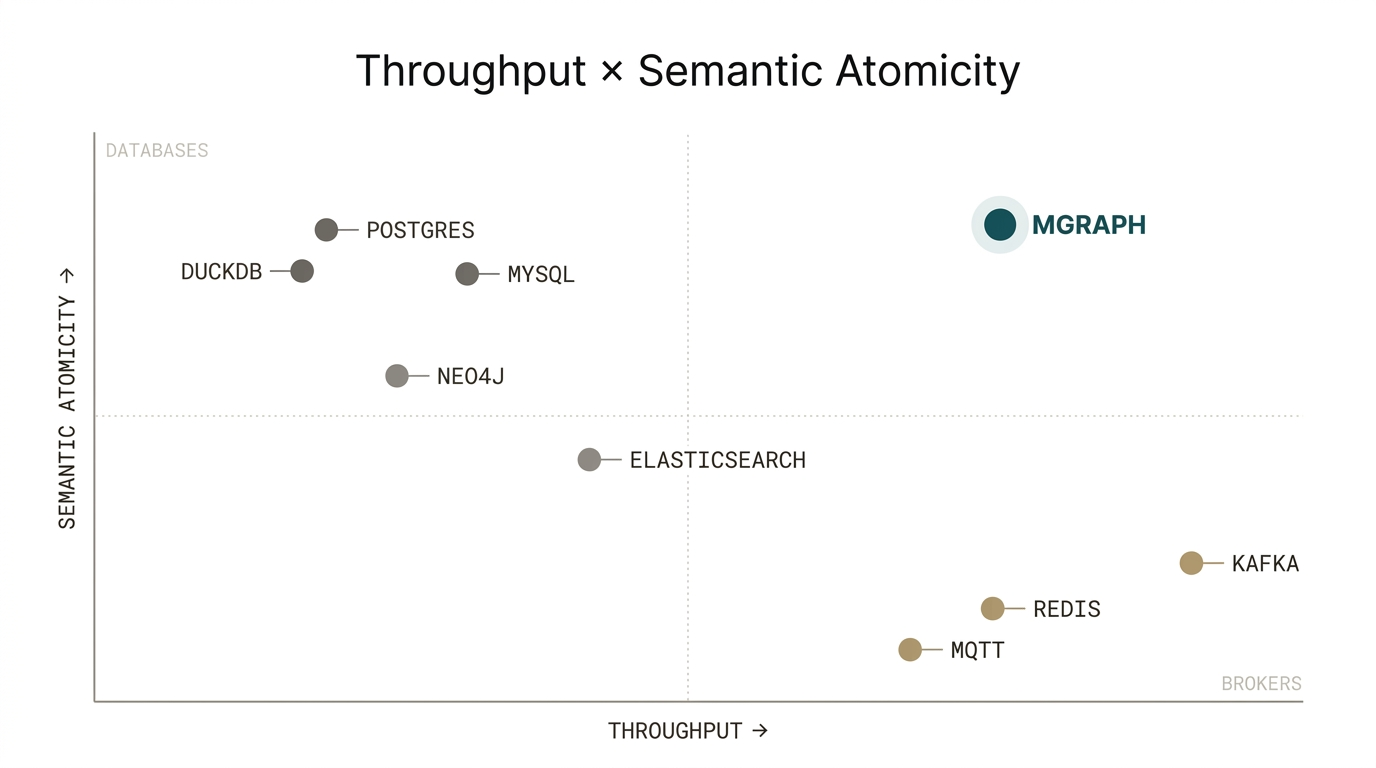
Fast or structured. Today you pick one.
Throughput versus semantic atomicity across today’s systems.
Brokers give up structure for speed. Databases pay for structure in latency. The upper-right corner is empty — that’s what we bench against.
The GPU layer.
The first vector database to leverage Apple Silicon’s GPU for retrieval — on-device, zero-dependency, on hardware every developer already owns.
The parallel query surface.
CPU and GPU, coordinated on shared memory. A class of database operations available only on Apple Silicon.