AGI & Real-time composition of intelligence pipelines.
An execution engine for Intelligence pipelines as directed graphs. Search, infer, reason, train, coordinate — executed in parallel across CPU and GPU cores.
The speeding up of intelligence pipelines
The ability to perform ad hoc complex analysis has always been in the realm of data scientists. The ability to construct complex static queries or multi-step pipelines has been with data engineers, or in the case of AI/ML, the AI/ML engineers.
The speed in which these analyses or queries or pipelines are being constructed is shrinking. An AI research agent that launches swarms of children agents to perform its tasks and report rarely has the exact shape of what they need programmed into them — they are adaptive to the requirements of the moment. Simple web search? Single agent. Complex research task? The shape is decided by the complexity of the task.
And the tools and datasets that such pipelines use is also becoming fluid — an uploaded CSV there, applying Python on it directly. An integrated data lake here with explicit query tooling.
This trend — the shortening of time-to-analysis, and the depth of analysis available — is likely to continue well into the next decade. Safe bet. IT is also likely that these types of analysis will begin to cross traditional borders as data and AI services become ubiquitous.
And very importantly, we think that these kinds of pipelines will make their way to the edge, and then all the way to the device. In fact they already are.
The shift is visible in how queries are evolving. Static queries gave way to dynamic plans. Dynamic plans are giving way to generated plans — where an inference step reasons about the task and emits a pipeline on the fly. LLM tool-use is already doing this: an agent decides it needs to search, then filter, then run inference on the results, composing a multi-step pipeline at runtime.
And yet, search, inference, and coordination still live in separate services stitched together with glue code. The search engine returns results. The inference service re-ranks them. The orchestrator wires them together. Each boundary is latency, complexity, and introduced brittleness.
What if the execution surface was singular?
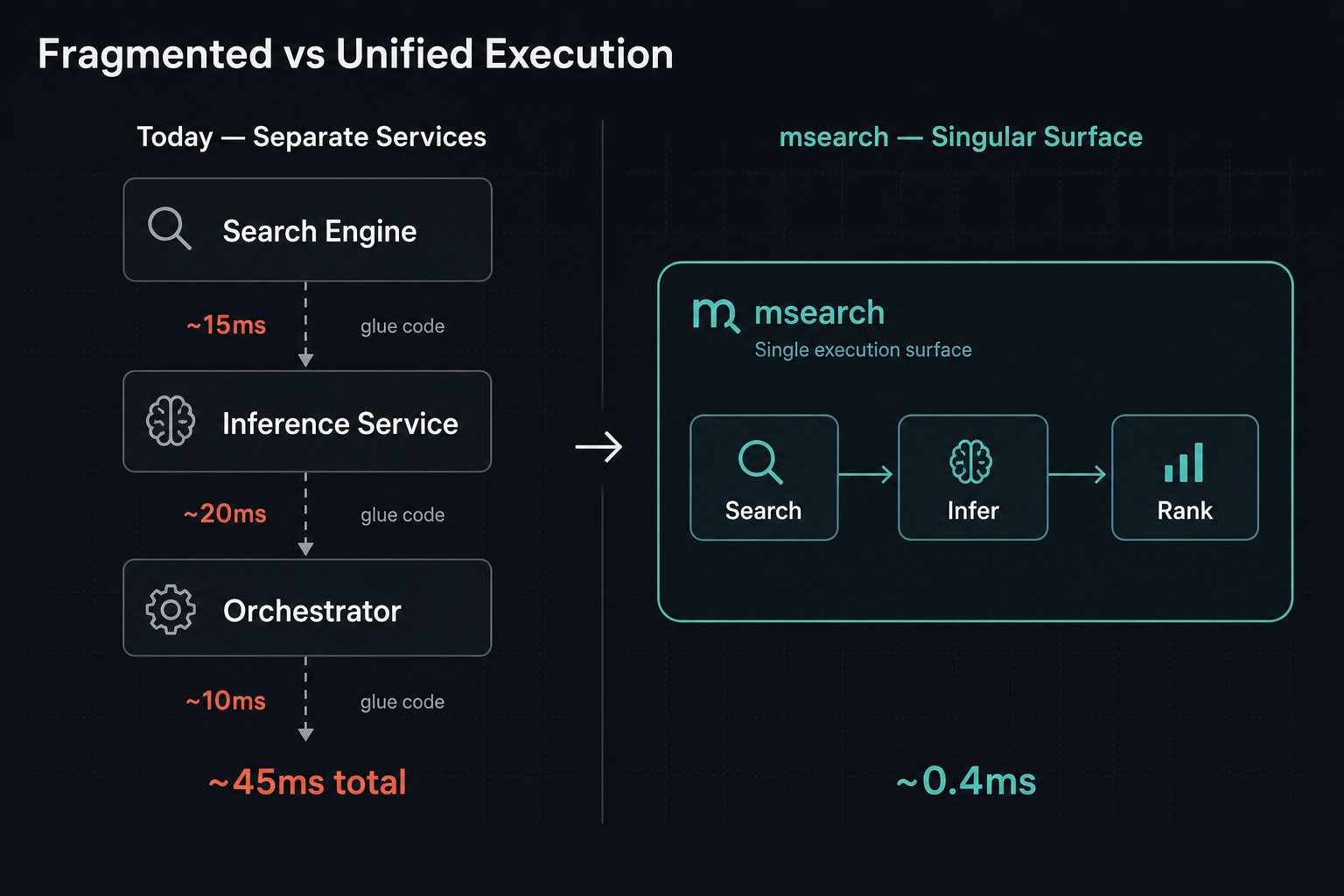
msearch
msearch is our answer to these trends. See project page here.
Still in protype stage, it isan engine for composable pipelines of intelligence primitives. By intelligence primitives I mean things like search, inference, indexing a dataset, training a model, launching a fleet of agents.
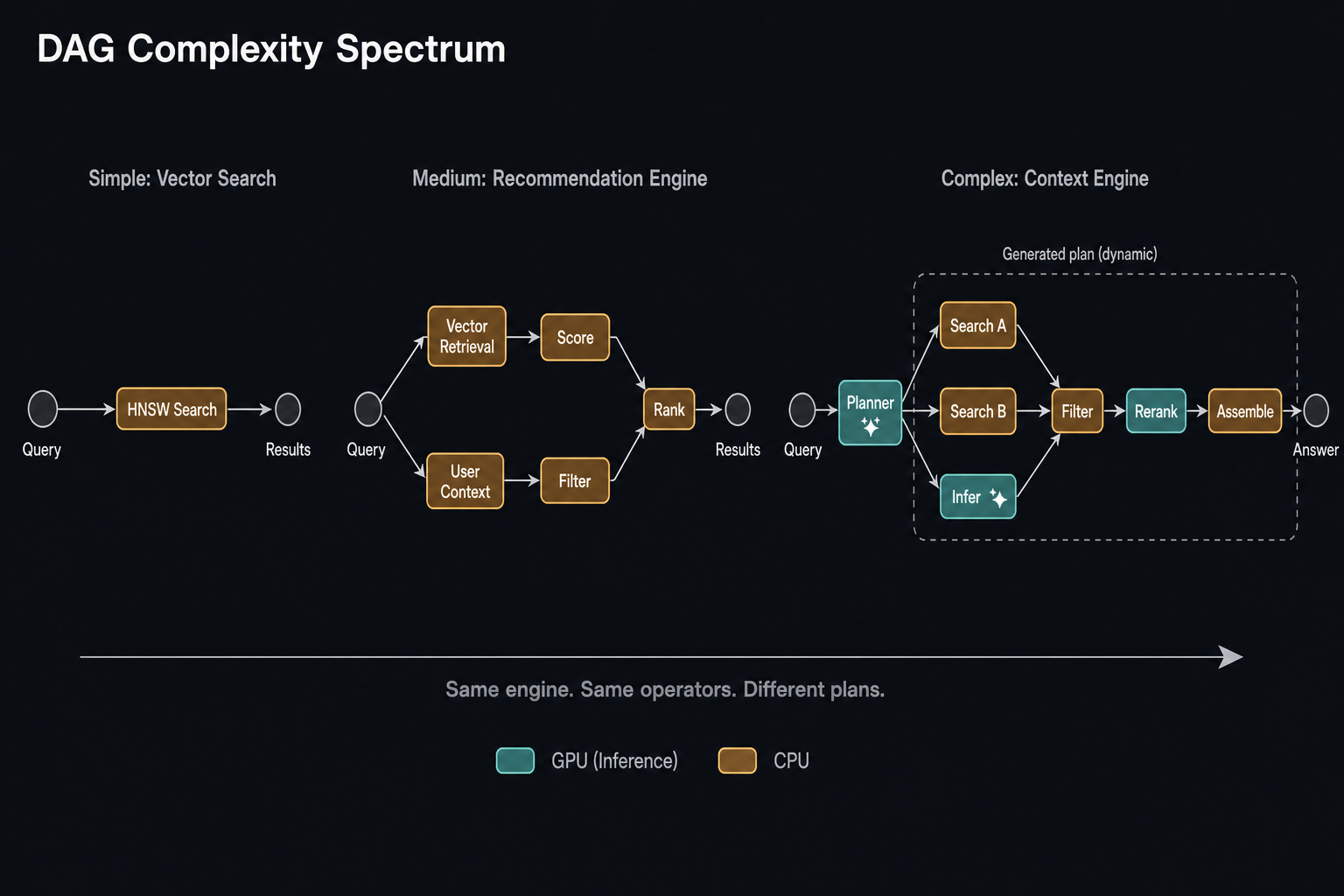
Every pipeline is a graph. A DAG to be precise. What a DAG offers is the ability to match the shape of the pipeline to the shape of the problem — parallel branches where work is independent, dependency resolution where it isn't, fan-out when the task demands breadth, fan-in when results need to converge.
The spectrum of what this enables is wide. At the simple end, a vector search is a single-node DAG — one index, one query, one result set. A hybrid search is a two-branch DAG — vector and lexical retrieval running in parallel, fused into one result. An inference pipeline is a linear chain with GPU dispatch — embedding, classification, or generation.
At the middle, a recommendation engine is a multi-branch DAG wiring together retrieval, user context, scoring, filtering, and ranking across multiple data sources. A model training run is a linear chain of epoch blocks.
At the far end, a context engine generates its own DAGs. A planner step analyses the query and the available data, reasons about what context to assemble, emits an optimised plan, and the execution engine runs it. This can be seen as intelligent query planning itself — after all, it's just a DAG.
This architecture also allows for a very efficient way to utilise the hardware available. CPU and GPU swimlanes that allow for parallel execution of operations across both cores, with each operation running on the core best suited to it.
On its architecture
Composability
Designed for composability, queries or pipelines (query plans) can be designed, precompiled (compiled query) and executed at runtime.
This could be a simple two-step vector search and rank, or it could be a highly sophisticated neural architecture that pops out 42 at the end.
Plans can be created in three ways: designed visually in a UI by wiring operators together, defined programmatically via API, or generated by an agent at runtime — an inference step that reasons about the task and emits a plan.
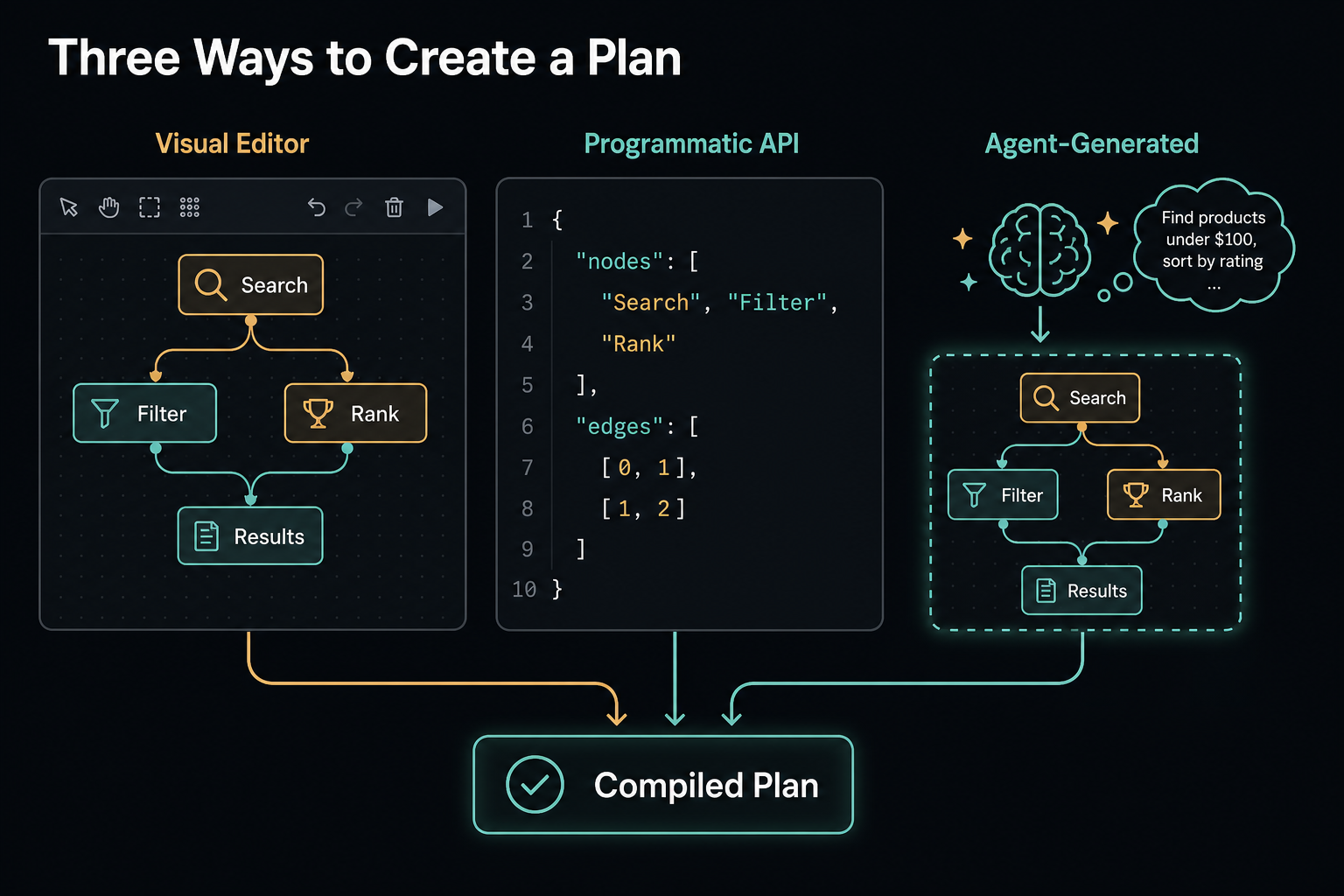
Queries are both compiled and parameterised:
Compiled. All static parameters are set, all memory references are resolved, all datasets loaded in memory. Designed so execution is about as fast as it can be. Compilation itself is in the millisecond range — it was simply a common use case that certain queries could be precomputed, and so they were.
Parameterised. Compiled queries are not static queries. Queries still have inputs only available at execution time — the search text, the user context, the filter criteria. Parameterisation handles this: static placeholders for dynamic inputs at runtime. The plan is compiled once; only the inputs change between executions.
→ A plan definition from the codebase:
{
"config": {
"index": "sift1m-hnsw.epVlCcLGHZY",
"beam_width": 64,
"threshold": 100
},
"compile": {
"page_size_hint": 4096
},
"inputs": {
"query_vector": { "type": "vector", "required": true },
"limit": { "type": "u32", "default": 10 }
},
"nodes": [
{ "op": "HNSWBeamSearchCpu", "args": { "index": "$config.index", "ef": "$config.beam_width" } },
{ "op": "FilterGt", "args": { "threshold": "$config.threshold" } },
{ "op": "TopK", "args": { "k": "$inputs.limit" } }
],
"edges": [[0, 1], [1, 2]]
}$config.* references are resolved at compile time — baked into the execution graph. $inputs.* references are resolved at execution time — the plan is compiled once, executed many times with different inputs.
Optimised for Apple Silicon
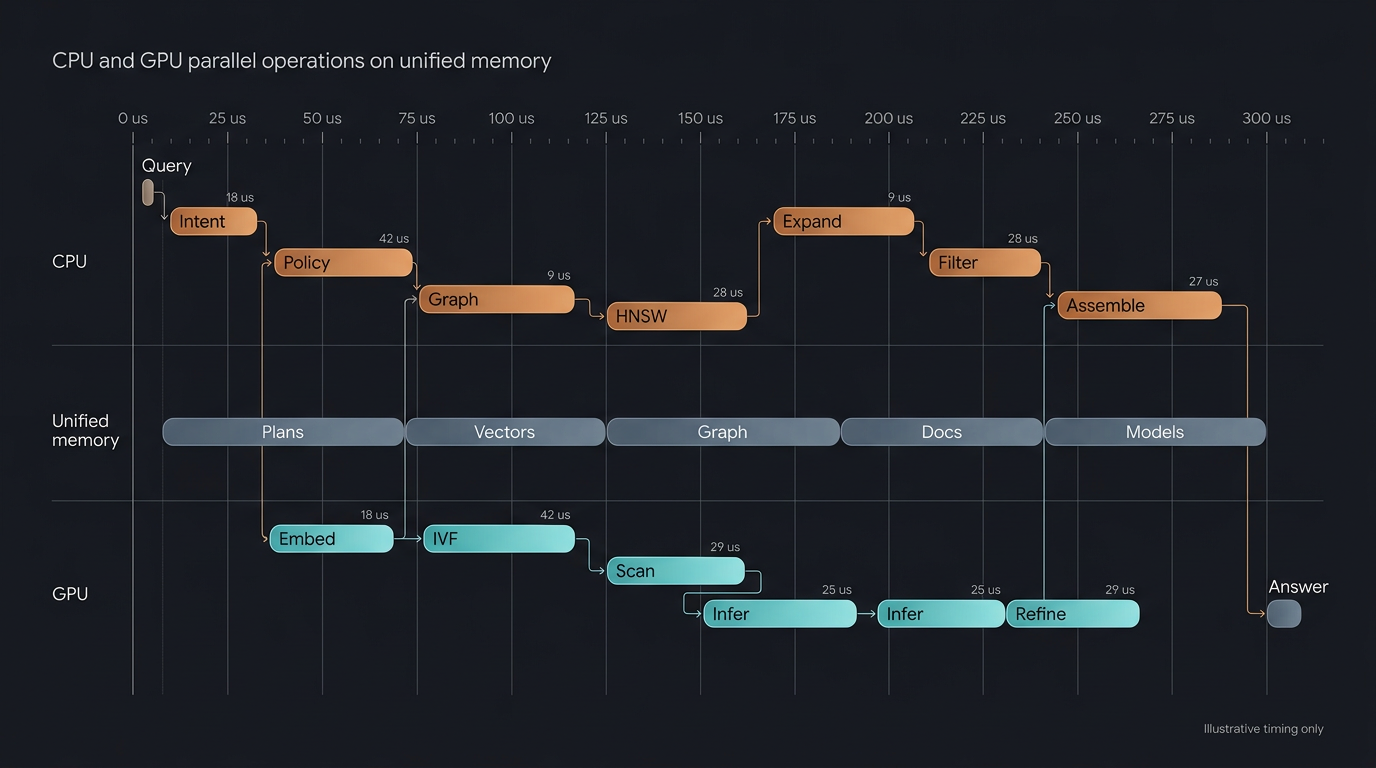
Although not strictly necessary, the Apple Silicon architecture brings a unique opportunity to the table — the ability to compose pipelines that run across CPU and GPU in parallel and in concert. The unified memory architecture means zero transfer tax. This allows for a level of composition that no other hardware can match.
A pipeline that interleaves CPU and GPU work — graph traversal → GPU similarity → CPU filter → GPU rerank — pays zero transfer cost at each boundary. On discrete hardware, each of those boundaries is a PCIe round-trip that kills performance, which is why existing databases simply do not do it. They choose a processor and stay on it, or they batch aggressively to amortise the cost.
msearch does not have to choose. The same data sits in the same memory, accessible by both processors in the same cycle. This is what makes the composability story real — not just "you can wire any operators together" but "you can wire CPU and GPU operators together and the execution cost is the operations themselves, not the transfers between them."
| Operation | Hardware | Why |
|---|---|---|
| Graph (HNSW, graph traverse) | CPU | Pointer chasing, random memory access |
| Small batch distance calculations | CPU (SIMD) | Batch too small for GPU dispatch overhead |
| Large batch vector ops (IVF) | GPU | Embarrassingly parallel |
| Index construction | GPU | Massive distance computation batches |
| Inference (transformers, embedders) | GPU | Matrix-heavy, high arithmetic intensity |
| Metadata filtering, predicates | CPU | Branching logic, irregular access |
An on-device intelligence runtime
A major advantage to this kind of engine is that it can run on device entirely — no cloud, no SaaS, no network transit costs. If we believe that on-device AI is the future of the industry, then msearch provides the ability to chain complex operations right next to the data on the device.
This makes for very agile and context-responsive types of intelligence systems that are not easily achieved with current stacks today. With no privacy or sovereignty concerns. No data sharing. No risk.
And the economics are hard to ignore: your Mac already has GPU cores sitting idle. No API keys, no per-query pricing, no server to provision. Likewise your iPhone and iPad.
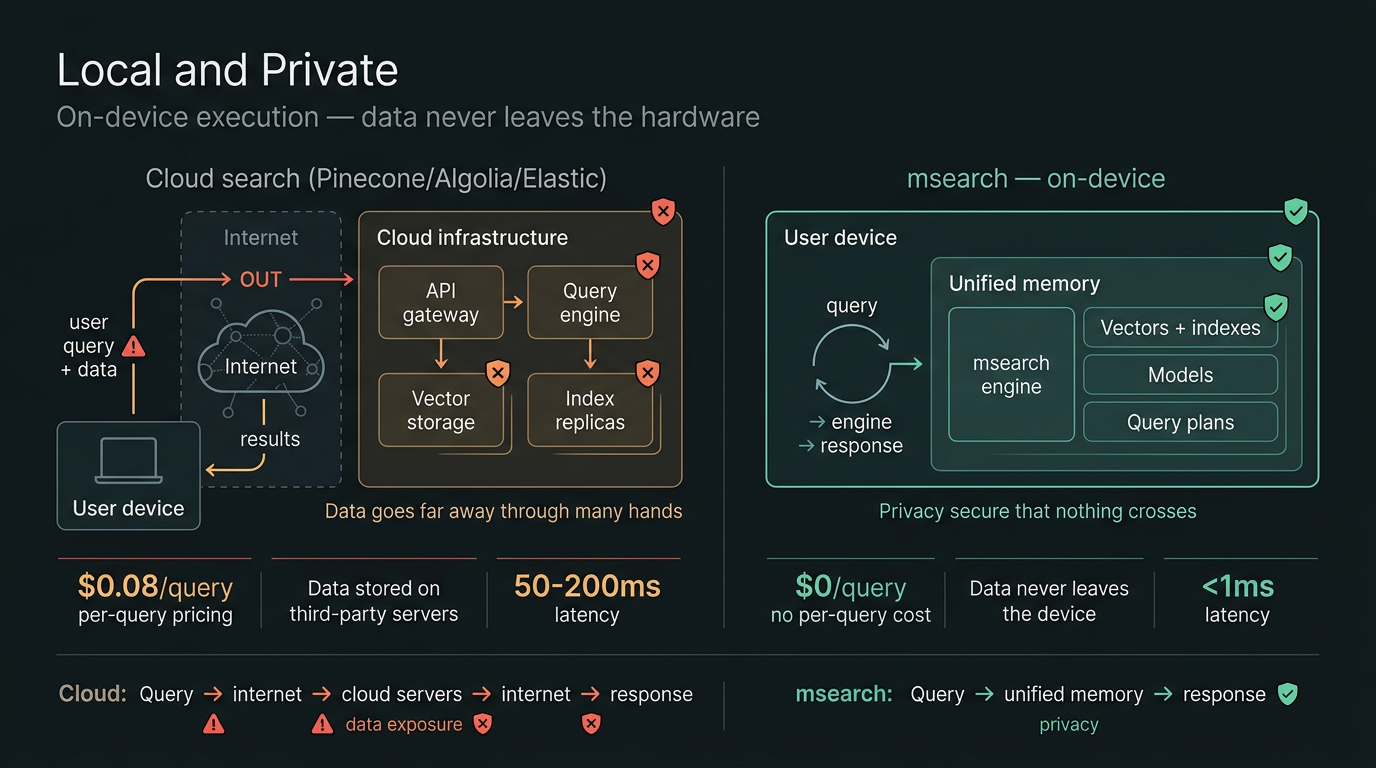
The on-device vision is a personal intelligence layer. Included on your device, or extending the same capabilities to your app.
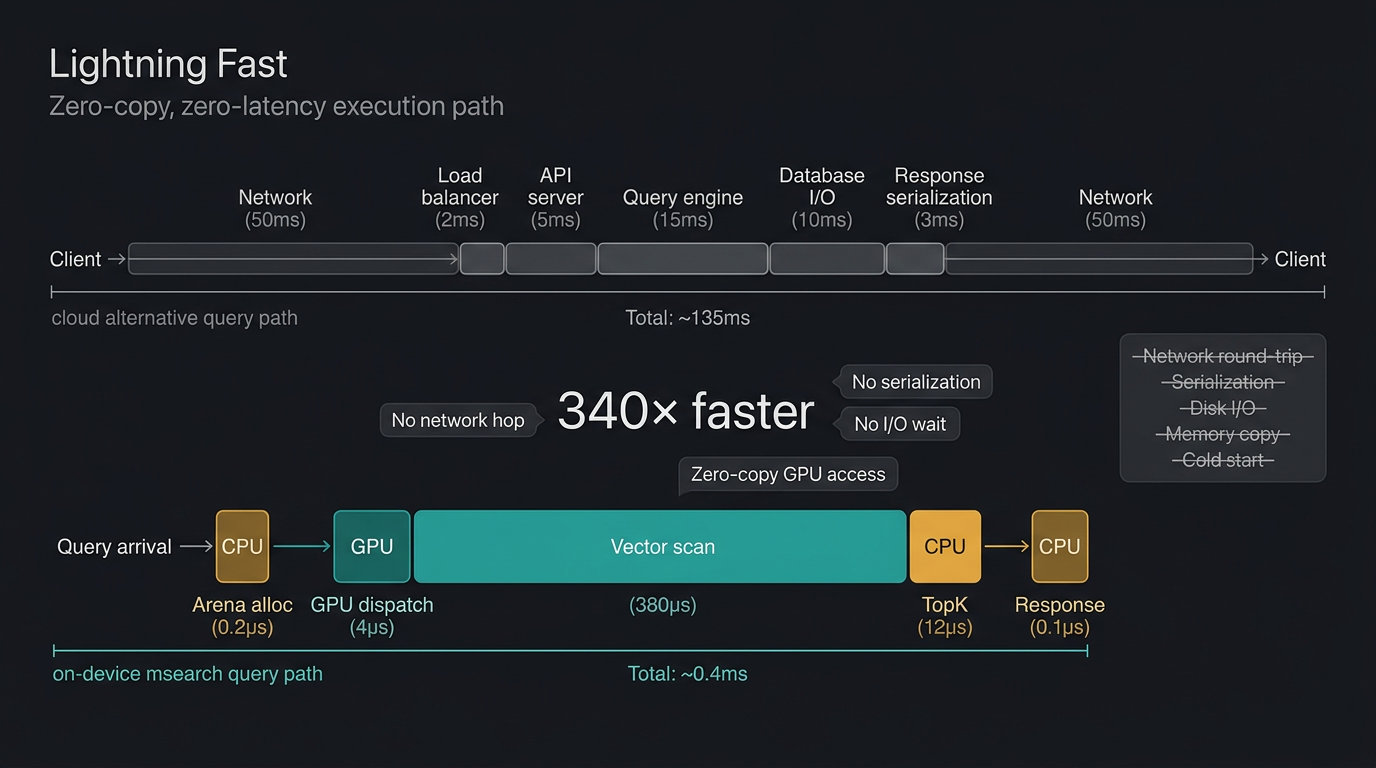
Designed for speed
The aim is not only to allow for lightning fast iteration on intelligence pipeline configuration — something that speeds up ideation or requirements to execution — but the execution itself is also optimised to the line. Hot memory loaded models, prewarmed queries so they are just a memory pointer away, paired with zero-copy arena memory architecture across operations and a DAG execution model that can execute hundreds of thousands of steps in parallel with nanosecond range overhead.
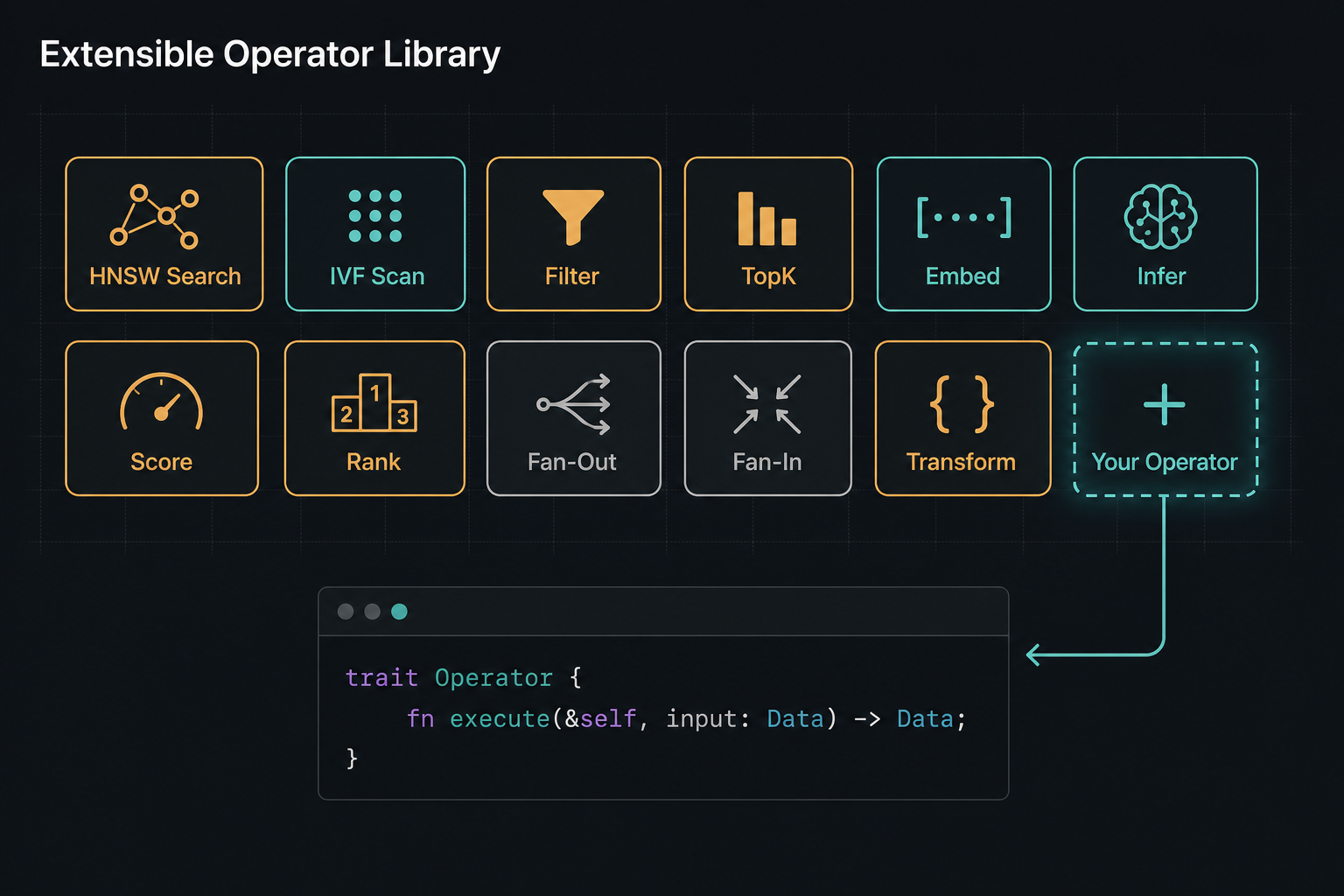
Designed for extensibility
We've built the software for our own use cases:
- Inference coordination on multi-model AI systems
- Agentic swarm coordination
- Multi-step GraphRAG systems
- GPU vs CPU vector search pipelines (HNSW, IVF, etc.)
But there are many more we have not. The software is designed to be extensible by users. If there is a particular primitive that doesn't quite meet requirements, or isn't there at all, it can be added.
→ Code snippet: the Operator trait and a minimal custom operator implementation
Where we are
We are still in early prototyping stage for this technology. Early benchmarks are very exciting. We are actively using it internally and with clients to flesh out the range of intelligence primitives and capabilities we need to make this technology super useful. There is quite a way before it is considered production ready.
Under the hood we are building this on mvec (project) — our Apple Silicon vector database, and mgraph (project) — our thread-safe data primitive for coordinating complex data types.
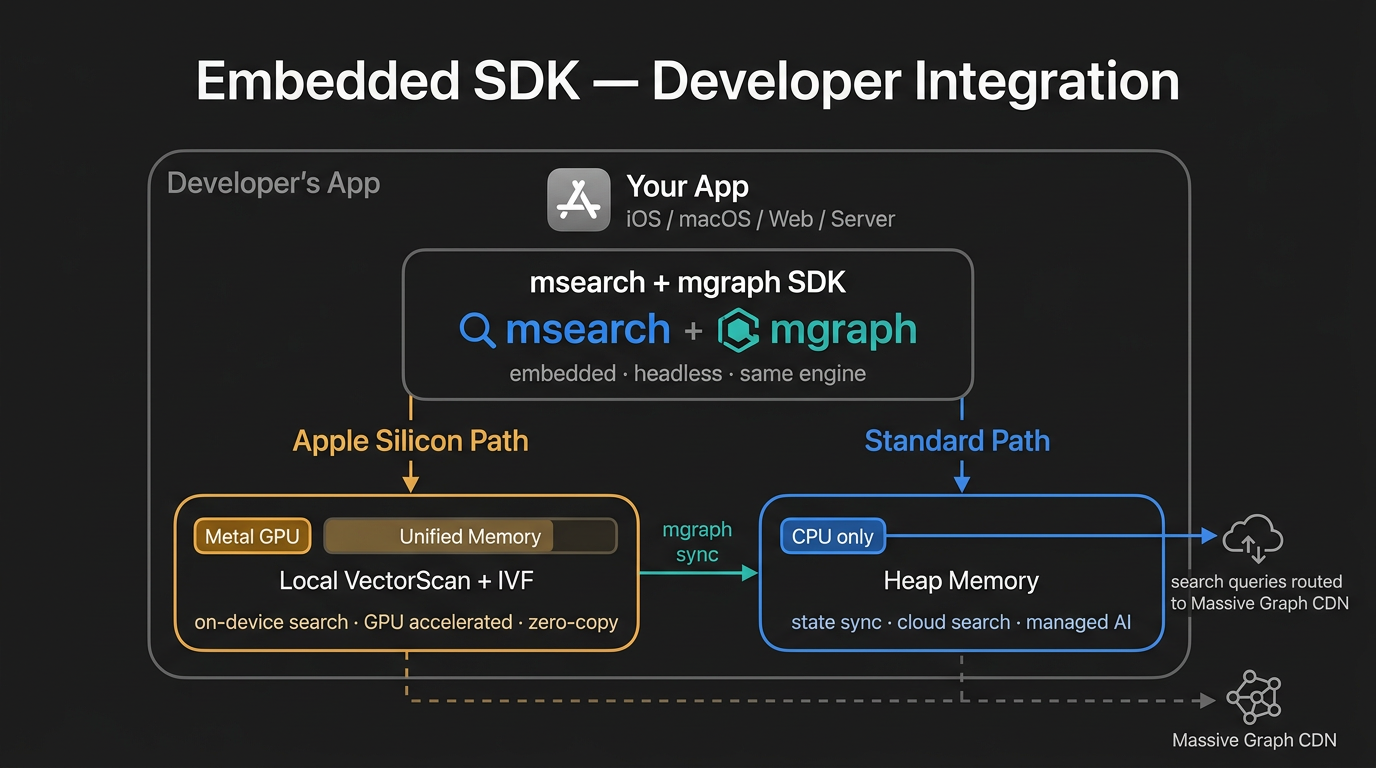
For the long term, we are looking at two goals:
- A standalone app and web app that can be used locally.
- An embeddable SDK to add composable intelligence pipelines to your apps.