The Three Mage Hypothesis.
A three-model neural architecture. Each trained on different datasets of a common problem space. Disagreements represent new information with lower correction-cost-to-improvement than traditional approaches.

Preamble: Named after the quantum computing AI system in my childhood favourite anime - Evangelion: Neon Genesis.
The Three Mage Hypothesis
Some problems do not have a single correct viewpoint. A codebase does not fully describe the runtime, a runtime does not describe its memory patterns — but all three in concert do. An organisation's knowledge is not captured by its schema alone, nor by the statistical shape of its data, nor by any specific context — but by the intersection of all three perspectives.
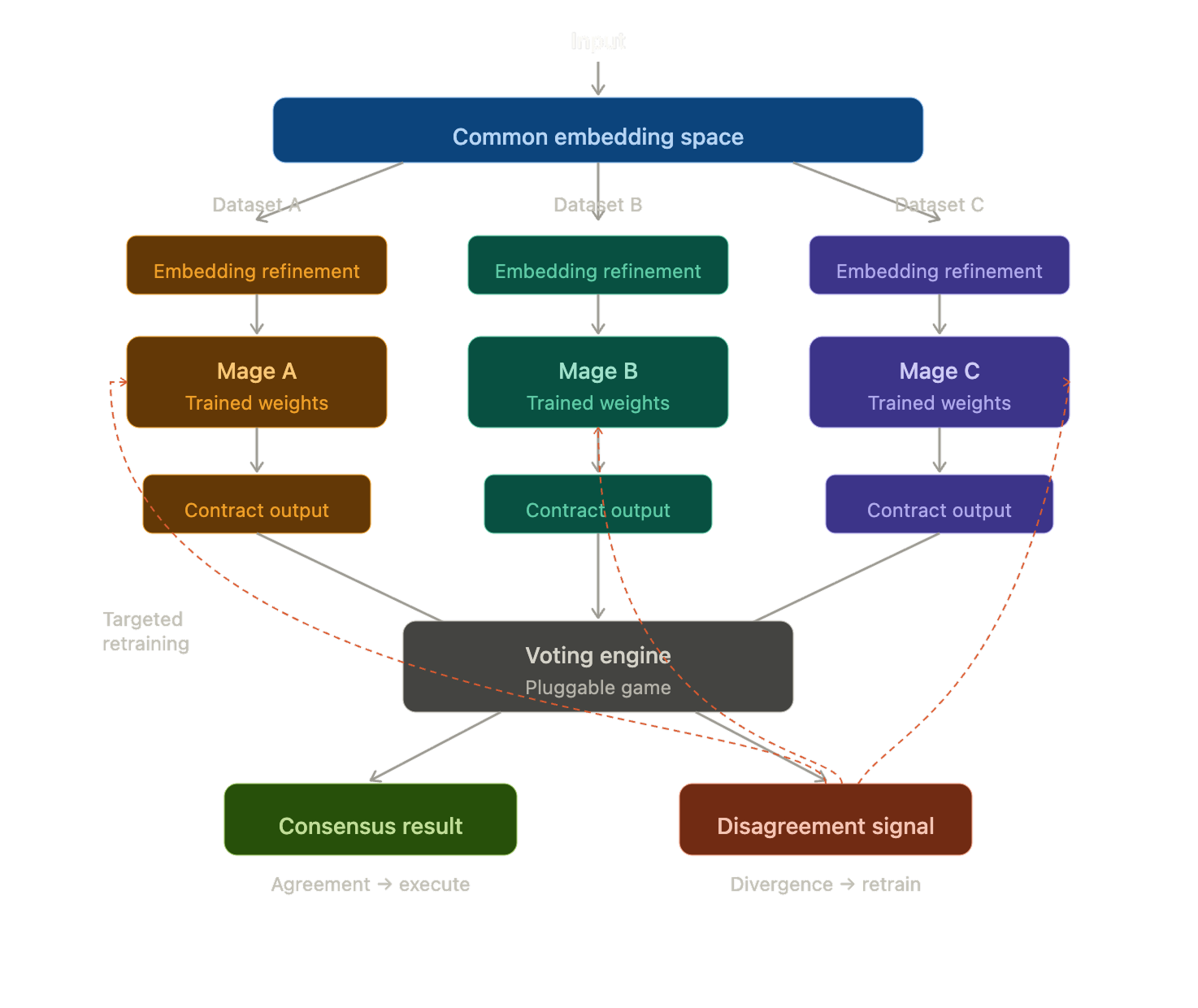
The Three Mage architecture is built on this observation. Three independent models, trained on different datasets representing different facets of the same underlying system, producing outputs that conform to a shared interface. They vote. When they agree, the system has confidence. When they disagree, that is high-value information — a map of where the system is either contested or weak.
That disagreement identifies where a model has learned false signal — and that identification is a more efficient training signal than retraining broadly. Rather than peeling the entire apple, you carve out the bad bits. Fewer examples, higher information density per correction, faster convergence.
The value proposition is efficiency — 80% of the improvement at 20% of the cost. This matters most on smaller devices with limited compute, where large-scale retraining is impractical but fast, incremental improvements on small models close to the data are exactly what is needed.
The idea
Take a problem — any problem with multiple observable dimensions. Train three small models, each on a genuinely different dataset representing a different facet of that problem. Not three views of the same data. Three different datasets, each capturing something the others cannot see.
Each model produces an output conforming to a shared typed interface. The models do not communicate with each other. They do not share weights, gradients, or internal representations. They see different things, independently, and report what they find in a common format.
A voting engine — external to the models, pluggable, interchangeable — receives the three outputs and applies a game. Majority rule for routine decisions. Veto for high-stakes. Quorum thresholds when confidence matters. The mages are unaware of which game is being played. They produce the same output regardless.
The vote becomes an input to the next round of analysis, to the next iteration of training, or to a multi-stage pipeline where successive votes narrow toward resolution. What the mages produce in one round shapes what they become in the next.
How this differs from what exists
Several existing multi-model approaches address similar problems with different assumptions.
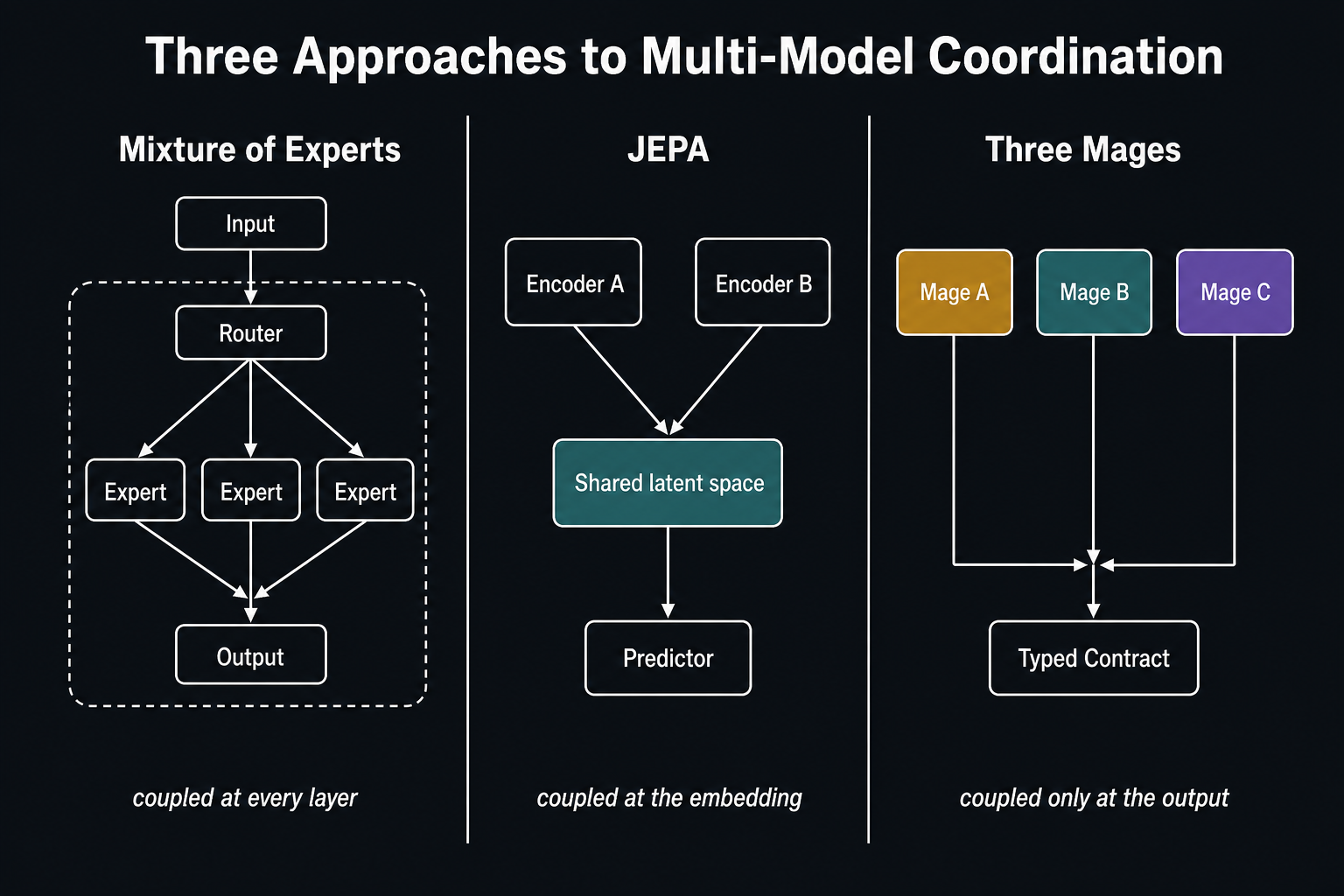
The closest existing pattern is Mixture of Experts. In MoE architectures — Mixtral, DeepSeek, Switch Transformer — a set of expert sub-networks live inside a single model, sharing an embedding space. A router examines the input and selects which experts activate. The experts share the same input representation and the same output space. They are specialists within one mind, not independent perspectives.
Three Mages is structurally different. The models are fully independent. They train on different data. They may (or may not) use different internal representations. There is no router selecting among them. The coordination happens at the output, not the input.
Joint Embedding Predictive Architectures — LeCun's JEPA — take the opposite approach to the same problem. Two encoders map different views of the same input into a shared latent space, with a predictor bridging them. The assumption is that good coordination requires representational alignment. Three Mages takes a different path. The models keep their own spaces and converge only at the output contract.
Standard ensembles average outputs across models that typically share training data and architecture, smoothing disagreement to reduce variance. Three Mages preserves disagreement as information. The models are trained on different data, may use different architectures, and the architecture's value comes from the independence of their perspectives — forcing them into agreement would erode the very thing that makes disagreement meaningful.
The contract
Every multi-model system needs a shared language for comparison. The question is how much of that language is implicit and how much is explicit.
In a shared embedding space, meaning lives in the geometry — distances, directions, clusters carry semantics across hundreds of dimensions. No field is named. The alignment is learned through joint training and is implicit throughout. This is a deep contract: aligned structure and aligned meaning.
In the Three Mage architecture, meaning lives in declared fields. Confidence is a float. Vote is an enum. Focus regions are weighted references to a shared problem space. The alignment is explicit, defined before training, and confined to the output surface. This is a thin contract: aligned structure, independent meaning.
Both are contracts. The difference is coupling depth. A shared embedding requires joint training or an alignment loss to keep the representations compatible — the models become coupled at every layer. A typed output contract requires only that each model learns to produce the declared fields — the internal representations are unconstrained.
The contract can take two forms. A fixed contract — a static structure known at training time, optimised tightly, rigid to change:
struct MageOutput {
confidence: f32, // 0.0–1.0
vote: Vote, // Yes | No | Abstain
focus_regions: [(NodeId, f32); 8], // top 8 weighted focus points
priority_rank: [NodeId; 5], // top 5 ranked priorities
}Or a generic contract — a structural pattern with a typed payload, where the voting mechanism operates on the confidence and vote fields while the domain-specific payload passes through to downstream execution:
struct MageOutput<T: Votable> {
confidence: f32,
vote: Vote,
focus: Vec<Weighted<T>>,
}
struct Weighted<T> {
item: T,
weight: f32,
}The first is simpler. The second allows the same architecture to serve different domains without retraining the coordination layer.
Two concrete cases
Enterprise search
Three mages, each trained on a different facet of organisational knowledge.
Mage 1: The first models the schema — the organisation's structure, ontologies, entity relationships, business model. Not the data itself. The shape of the container.
Mage 2: The second models the statistical profile of the data within that schema. Distributions, correlations, selectivity, cardinality. How data actually behaves within the structure. Again, not the data itself — the patterns.
Mage 3: The third models the user's context. Session history, query trajectory, long-term preferences, intent. The human dimension that neither the schema nor the statistics can capture.
A search query has expression in all three. The schema mage knows which entities are relevant. The statistical mage knows which paths through the data are likely to yield results. The context mage knows what this particular user is actually looking for. None holds the complete picture. The complete picture emerges from the vote.
Codebase intelligence
Three mages, each trained on a different facet of a running application.
Mage 1: The first models the code itself — source files, type definitions, dependency graphs, documentation. The static artefact. What the system is built from.
Mage 2: The second models execution pathways — call sequences, branch frequencies, hot paths. The most common routes through the code, strengthened by repetition like neural pathways in the brain. What the system actually does at runtime.
Mage 3: The third models memory state changes — typed mutation patterns, allocation and deallocation sequences, state transitions. Not the data in memory, but how it changes. The system's metabolism.
A running application has representation in all three. A bug might be invisible in the code, obvious in the pathway frequencies, and confirmed by an anomalous memory pattern. No single mage would catch it. The triangulation does.
The pattern
In both cases, the mages model aspects of the thing, not the thing itself. Each facet has expression within all three mages, but no single mage holds a complete representation. This is the design. The architecture assumes that the complete picture is too complex for any single model to hold — and that the attempt to force it into one representation loses the very distinctions that matter.
When they disagree
Arrow's impossibility theorem states that no ranked voting system with three or more alternatives can simultaneously satisfy fairness, consistency, and non-dictatorship. One axiom must break. For most multi-model systems, this is a problem to solve — find a weighting scheme, apply a meta-learner, smooth the disagreement away.
The Three Mage Hypothesis treats it as a feature.
For binary votes — yes or no — May's theorem provides a clean result: simple majority is the unique fair mechanism. The abstain option is the escape valve that makes this workable with three voters. A mage that lacks sufficient confidence abstains rather than guessing, allowing the other two to resolve.
Four states emerge from three voters:
Unanimous agreement — all three converge. Highest confidence. Execute immediately.
Majority — two agree, one dissents. Clear direction, dissent recorded. The dissenting mage may be wrong (training opportunity) or may be seeing something the others miss (worth investigating).
Split with abstain — one yes, one no, one abstain. No majority. The abstention prevented resolution. More information needed.
Full deadlock — irreconcilable disagreement. No Condorcet winner. Arrow's theorem in action. This is not a system failure. It is the architecture telling you that the problem is genuinely multi-faceted — the three perspectives see fundamentally different things, and flattening them into a single answer would lose information. Preserve the disagreement. Surface it. Let the consumer decide.
The voting mechanism itself is external to the models and pluggable. Majority for routine queries. Veto for high-stakes decisions. Borda count for ranked focus regions. The mages produce the same contract output regardless of which game is applied downstream.
Disagreement as a training signal
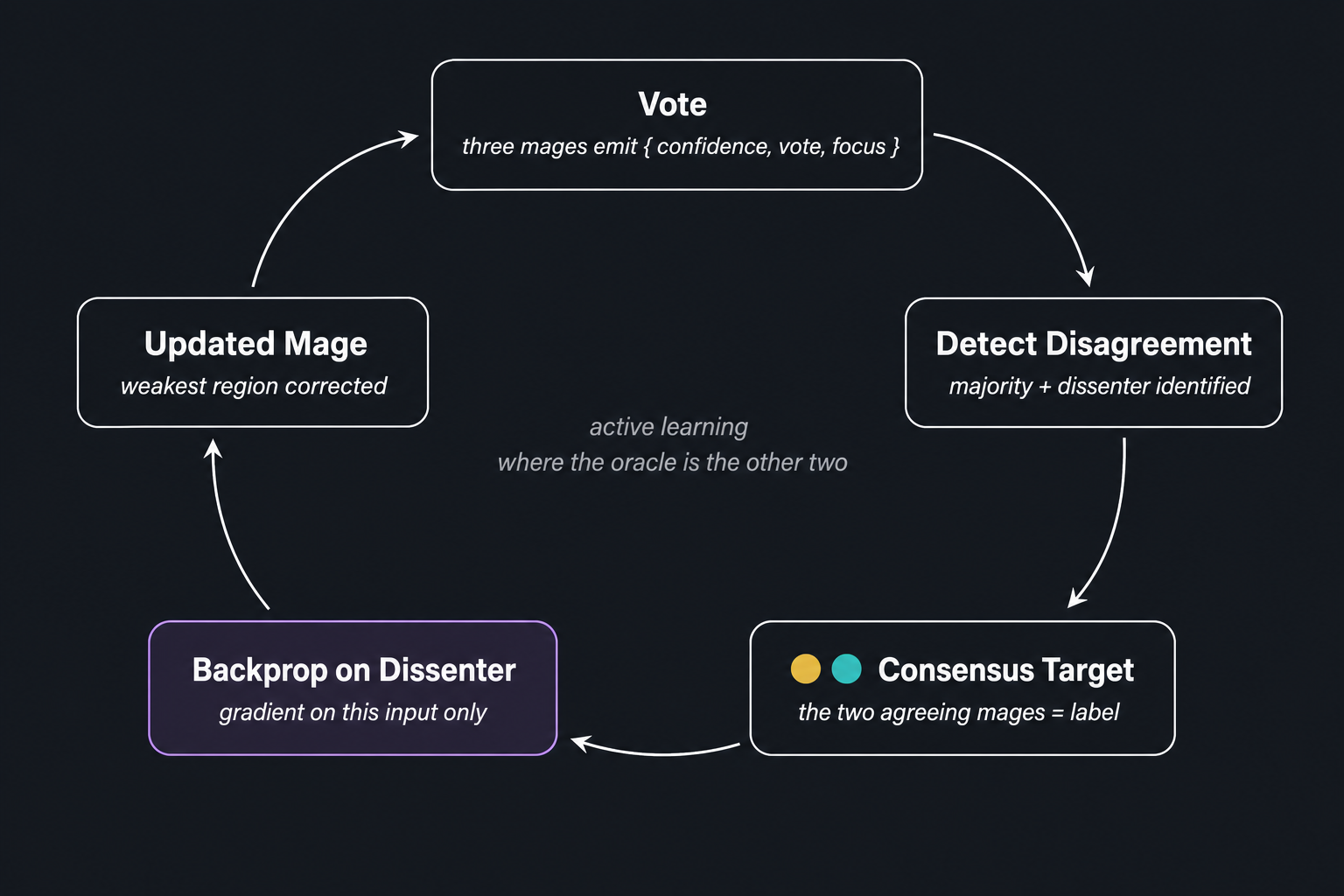
The most valuable output of the voting mechanism is not agreement — it is structured disagreement.
When two mages agree and one dissents, the system has identified a specific region of the problem space where that model is weak. The consensus of the other two provides the target — not an external oracle, not a human annotator, but the triangulated perspective of the other two facets.
This creates a training pathway. The vote identifies the input region where a mage is wrong. The consensus provides the target label. A forward pass through the dissenting model on that specific input, followed by backpropagation against the consensus target, produces a gradient that points directly at the weights responsible for the error. Update those weights. Leave everything else alone.
This is active learning where the oracle is the other two mages. The query strategy is voting disagreement rather than uncertainty sampling. And it is substantially more targeted than general retraining — instead of computing loss across the full training set and nudging every weight a little, the system trains exclusively on inputs where the other mages have identified weakness, with targets provided by their consensus.
Each correction shaves away the weakest region of a model's parameter space. Progressive, surgical, targeted. The model improves where it is demonstrably wrong, without disturbing the regions where it is already correct.
The critical distinction: not all disagreement should be resolved. Resolvable disagreement — where one mage is simply incorrect — feeds retraining. Structural disagreement — where the mages see genuinely different things and no single answer is right — is preserved as information. The Arrow's theorem classification provides the formal mechanism for distinguishing the two. Train on the first. Report the second.
This could operate as a single round — one vote, one correction cycle. Or as a multi-stage analysis, each round tabling disagreements and refining until the system stabilises. Or as a continuous training loop, where disagreement regions from production queries feed the next iteration of model improvement. The architecture supports all three modes.
The cost of improvement
The vote becomes an input to the next round of analysis, to the next iteration of training, or to a multi-stage pipeline where successive votes narrow toward resolution. What the mages produce in one round shapes what they become in the next.
This has a measurable cost advantage. Traditional model improvement retrains across the full dataset — every example, every weight, every epoch. Most of that compute is spent reinforcing things the model already knows. The signal-to-noise ratio of a general training pass is low relative to the compute invested.
Disagreement-driven retraining inverts this. The voting mechanism surfaces a curated subset of inputs — specifically the inputs where the model is weakest. Training on that subset requires fewer examples to achieve the same improvement. In active learning literature, targeted sample selection routinely achieves equivalent accuracy with 10–100× fewer labelled examples than random sampling. If disagreement-identified inputs follow the same pattern, the training set per improvement cycle shrinks by an order of magnitude.
The convergence metric is equally direct: how many rounds of vote → retrain → re-vote until the disagreement surface stabilises? Each round should reduce the area of contention. If the system converges in a handful of cycles where traditional retraining requires dozens of full epochs, the cost per unit of improvement drops substantially.
Both metrics — sample efficiency and convergence rate — are measurable. They will be measured.
What comes next
The hypothesis is laid out. The architecture is described. What remains is validation.
The first question: does representational independence actually preserve orthogonal failure modes? If the three mages converge to similar internal representations despite training on different data, the architecture loses its advantage. The diversity of perspectives must survive training.
The second question: does targeted retraining via voting disagreement converge faster than standard approaches? The claim is that disagreement-selected inputs are more information-dense than random or uniformly sampled training data. This is measurable.
The third question: does the thin contract lose critical information compared to a shared embedding? The architecture trades representational depth for independence. If the contract is too thin — if the voting surface is insufficient for meaningful comparison — the system cannot distinguish genuine disagreement from noise.
The first experiment will pick one concrete case, train three small models on genuinely different datasets, implement the voting mechanism, and measure. Does the system identify weaknesses that individual models cannot? Does targeted retraining outperform baseline? Does structural disagreement correlate with genuinely ambiguous inputs?
The implementation and results will follow in a subsequent article.